10. Random variables#
Recommended reference: Wasserman [Was04], Sections 1.1–1.3, 2.1–2.2 and 3.1–3.3.
10.1. Introduction#
A probability distribution assigns probabilities (real numbers in \([0,1]\)) to elements or subsets of a sample space. The elements of a sample space are called outcomes, subsets are called events.
The space of outcomes is usually of one of two kinds:
some finite or countable set (modelling the number of particles hitting a detector, for example), or
the real line, a higher-dimensional space or some subset of one of these (modelling the position of a particle, for example).
These correspond to the two types of probability distributions that are usually distinguished: discrete and continuous probability distributions.
10.2. Random variables#
A random variable is any real-valued function on the space of outcomes of a probability distribution. Random variables can often be interpreted as observable (scalar) quantities such as length, position, energy, the number of occurrences of some event or the spin of an elementary particle.
Any random variable has a distribution function, which is how we usually describe random variables. We will look at distribution functions separately for discrete and continuous random variables.
10.3. Discrete random variables#
A discrete random variable \(X\) can take finitely many or countably many distinct values \(x_0,x_1,x_2,\ldots\) in \(\RR\). It is characterised by its probability mass function (PMF).
Definition 10.1 (Probability mass function)
The probability mass function of the discrete random variable \(X\) is defined by
One can visualise a probability mass function by placing a vertical bar of height \(f_X(x)\) at each value \(x\), as in Fig. 10.1.
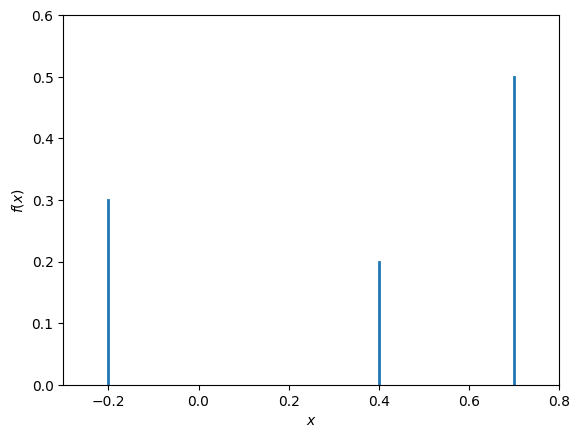
Fig. 10.1 Probability mass function of a discrete random variable.#
Property 10.1 (Properties of a probability mass function)
Since the \(f_X(x)\) are probabilities, they satisfy
Since the \(x_i\) are all the possible values and their total probability equals 1, we also have
10.4. Continuous random variables#
For a continuous random variable \(X\), the set of possible values is usually a (finite or infinite) interval, and the probability of any single value occurring is usually zero. We therefore consider the probability of the value lying in some interval. This can be described by a probability density function (PDF).
Definition 10.2 (Probability density function)
The probability density function of the continuous random variable \(X\) is a function \(f_X\colon\RR\to\RR\) such that
To visualise a continuous random variable, one often plots the probability density function, as in Fig. 10.2.
Property 10.2 (Properties of a probability density function)
\(f_X(x)\ge0\) for all \(x\);
\(\int_{-\infty}^\infty f(x)dx=1\).
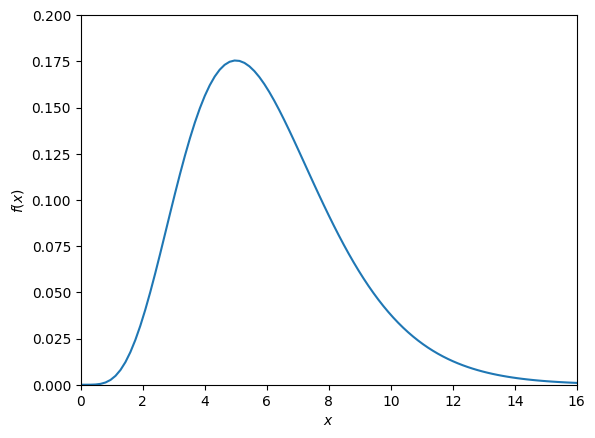
Fig. 10.2 Probability density function of a continuous random variable.#
10.5. Expectation and variance#
The expectation (or expected value, or mean) of a random variable is the average value of many samples. The variance and the closely related standard deviation measure by how much samples tend to deviate from the average.
Definition 10.3 (Expectation)
The expectation or mean of a discrete random variable \(X\) with probability mass function \(f_X\) is
The expectation or mean of a continuous random variable \(X\) with probability density function \(f_X\) is
The expectation of \(X\) is often denoted by \(\mu\) or \(\mu(X)\).
Definition 10.4 (Variance and standard deviation)
The variance of a (discrete or continuous) random variable \(X\) with mean \(\mu\) is
The standard deviation of \(X\) is
It is not hard to show (see Exercise 10.3) that
10.6. Cumulative distribution functions#
Besides the probability mass functions and probability density functions introduced above, it is often useful to look at cumulative distribution functions. Among other things, these have the advantage that the definition is the same for discrete and continuous random variables.
Definition 10.5 (Cumulative distribution function)
The cumulative distribution function of a (discrete or continuous) random variable \(X\) is the function \(F_X\colon\RR\to\RR\) defined by
If \(X\) is a discrete random variable, this comes down to
This is illustrated in Fig. 10.3.
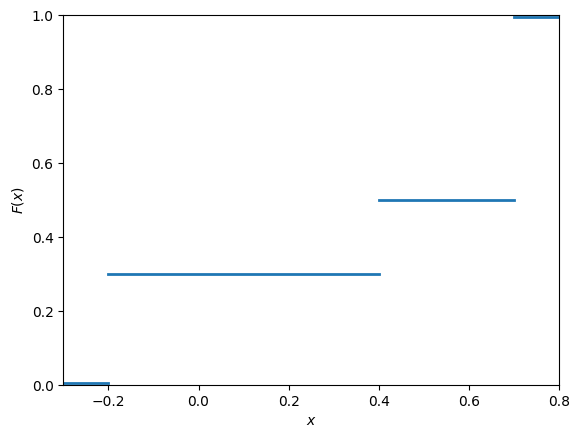
Fig. 10.3 Cumulative distribution function of the discrete random variable from Fig. 10.1.#
Now suppose \(X\) is a continuous random variable. Taking the limit \(a\to-\infty\) in the definition of the probability density function, we obtain
This is illustrated in Fig. 10.4.
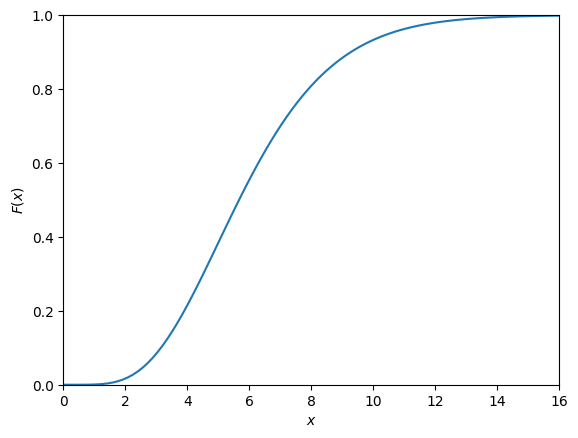
Fig. 10.4 Cumulative distribution function of the continuous random variable from Fig. 10.2.#
10.7. Independence and conditional probability#
Recommended reference for this subsection: Wasserman [Was04], Sections 2.5–2.8.
Informally speaking, two random variables \(X\) and \(Y\) are independent if knowledge of the value of one of the two does not tell us anything about the value of the other. However, knowledge of one random variable often does give you information about another random variable. This is encoded in the concept of conditional probability distributions.
To make the notions of indepence and conditional probability precise, we need two further concepts: the joint probability mass function \(P(X=x\text{ and }Y=y)\) in the case of discrete random variables, and the joint probability density function \(f_{X,Y}(x,y)\) in the case of continuous random variables. These describe the joint probability distribution of the two random variables \(X\) and \(Y\). Rather than defining these here, we refer to Wasserman [Was04], Section 2.5. We only note the relationship with the corresponding single-variable functions. If \(X\) and \(Y\) are discrete random variables, we have
Similary, if \(X\) and \(Y\) are continuous random variables, the relationship is given by
In this situation, the distributions of \(X\) and \(Y\) individually are called the marginal distributions of the joint distribution of \(X\) and \(Y\).
Definition 10.6 (Independence of random variables)
Two discrete random variables \(X\) and \(Y\) are independent if for all possible values \(x\) and \(y\) of \(X\) and \(Y\), respectively, we have
Similarly, two continous random variables \(X\) and \(Y\) are independent if their probability density functions satisfy
Definition 10.7 (Conditional probability)
Consider two discrete random variables \(X\) and \(Y\), and a value \(y\) such that \(P(Y=y)>0\). The conditional probability of \(x\) given \(y\) is defined as
Analogously, consider two continuous random variables \(X\) and \(Y\), and a value \(y\) such that \(f_Y(y)>0\). The conditional probability of \(x\) given \(y\) is defined as
In Exercise 10.5, you will show that if two random variables \(X\) and \(Y\) are independent, then the distribution of \(X\) given a certain value of \(Y\) is the same as the distribution of \(X\).
10.8. Covariance and correlation#
Recommended reference for this subsection: Wasserman [Was04], Section 3.3.
Definition 10.8 (Covariance of two random variables)
Let \(X\) and \(Y\) be random variables with means \(\mu_X\) and \(\mu_Y\), respectively. The covariance of \(X\) and \(Y\) is
The correlation of \(X\) and \(Y\) is
The covariance can be expressed in a way reminiscent of (10.1) as follows (see Exercise 10.6):
Using the Cauchy–Schwarz inequality (see Exercise 8.4), one can show that the correlation satisfies \(-1\le\rho(X,Y)\le 1\).
10.9. Moments and the characteristic function#
Note
The topics in this section are not necessarily treated in a BSc-level probability course. We include them both because they have applications in physics and data analysis, and because they connect nicely to various other topics in this module.
Definition 10.9 (Moments of a random variable)
Let \(X\) be a random variable. For \(j=0,1,\ldots\), the \(j\)-th moment of \(X\) is the expectation of \(X^j\).
Concretely, for a discrete random variable \(X\), this means that the \(j\)-th moment is given by
For a continuous random variable, the \(j\)-th moment can be expressed as
Note that we have already encountered the first and second moments in the definition of the expectation (Definition 10.3) and in the formula (10.1) for the variance.
It is sometimes convenient to collect all the moments of \(X\) in a power series. For this, we include the moment generating function of \(X\).
Definition 10.10 (Moment generating function of a random variable)
Let \(X\) be a random variable. The moment generating function of \(X\) is the following function of a real variable \(t\):
This definition may look a bit mysterious at first sight. Assuming that we can treat the random variable \(X\) in a similar way as an ordinary real number, we can compute the Taylor series of \(M_X(t)\) via the usual formula (see The exponential function), which will reveal how \(M_X(t)\) encodes the moments of \(X\):
In some situations, it is better to use a variant called the characteristic function. (One reason is that the characteristic function is defined for every probability distribution; the moment generating function does not exist for ‘badly behaved’ distributions like the Cauchy distribution that we will see in Definition 11.1.)
Definition 10.11 (Characteristic function of a random variable)
Let \(X\) be a random variable. The characteristic function of \(X\) is the following (complex-valued) function of a real variable \(t\):
A similar computation as above gives
On the other hand, using the probability density function \(f_X\), we can also express \(\phi_X(t)\) in a different way, namely as
This means that \(\phi_X(t)\) is essentially the Fourier transform of \(f_X\) (see Definition 3.1); more precisely, the relation is given by
The characteristic function can be used to give a proof of the central limit theorem, which will be introduced in Section 12.3.
10.10. Exercises#
Exercise 10.1
Show that the function
is a probability mass function.
Exercise 10.2
Which of the following functions are probability density functions?
\(f(x)=\begin{cases} 0& \text{if }x<0\\ x\exp(-x)& \text{if }x\ge 0\end{cases}\)
\(f(x)=\begin{cases} 1/4& \text{if }-2\le x\le 2\\ 0& \text{otherwise}\end{cases}\)
\(f(x)=\begin{cases} \frac{3}{4}(x^2-1)& \text{if }-2\le x\le 2\\ 0& \text{otherwise} \end{cases}\)
Exercise 10.3
Deduce (10.1) from the definition of the variance.
Exercise 10.4
Consider a continuous random variable \(X\) with probability density function
Compute the expectation and the variance of \(X\).
Exercise 10.5
Consider two discrete random variables \(X\) and \(Y\). Show that if \(X\) and \(Y\) are independent, we have
(Intuitively, this means that observing \(Y\) tells us nothing about the probability of observing a certain value of \(X\).)
Exercise 10.6
Let \(X\) and \(Y\) be random variables. Prove the formula (10.2).
Exercise 10.7
Show that the moment generating function of the random variable from Exercise 10.4 is given by
Exercise 10.8
Let \(X\) be a random variable with moment generating function \(M_X(t)\). Show that for all \(n\ge0\), the \(n\)-th moment of \(X\) can be computed as the \(n\)-th derivative of \(M_X(t)\) at \(t=0\), i.e.