12. Central limit theorem#
Recommended reference: Wasserman [Was04], Sections 5.3–5.4.
The central limit theorem is a very important result in probability theory. It tell us that when we have \(n\) independent and identically distributed random variables, the distribution of their average (up to suitable shifting and rescaling) approximates a normal distribution as \(n\to\infty\).
12.1. Sample mean#
Consider a sequence of independent random variables \(X_1, X_2, \ldots\) distributed according to the same distribution function (which can be discrete or continuous). We say \(X_1, X_2, \ldots\) are independent and identically distributed (or i.i.d.).
Note
We saw the notion of independence of two random variables in
def-indep. For a precise definition of independence of an
arbitrary number of random variables, see Section 2.9 in
Wasserman [Was04].
Definition 12.1
The \(n\)-th sample mean of \(X_1,X_2,\ldots\) is
Note that \(\overline{X}_n\) is itself again a random variable.
12.2. The law of large numbers#
As above, consider i.i.d. samples \(X_1, X_2, \ldots\), say with distribution function \(f\). We assume that \(f\) has finite mean \(\mu\). The law of large numbers says that the \(n\)-th sample average is likely to be close to \(\mu\) for sufficiently large \(n\).
Theorem 12.1 (Law of large numbers)
For every \(\epsilon>0\), the probability
tends to \(0\) as \(n\to\infty\).
Note
The above formulation is known as the weak law of large numbers; there are also stronger versions, but the differences are not important here.
Fig. 12.1 illustrates the law of large numbers for the average of the first \(n\) out of 1000 dice rolls.
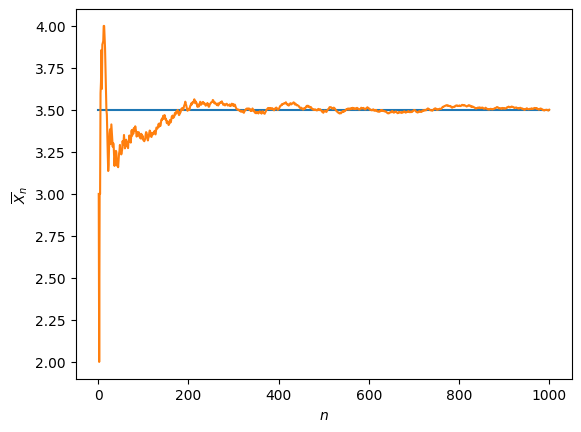
Fig. 12.1 Illustration of the law of large numbers: average of \(n\) dice rolls as \(n\to\infty\).#
Warning
If the mean of the distribution function \(f\) does not exist, then the law of large numbers is meaningless. This is illustrated for the Cauchy distribution (see Definition 11.1) in Fig. 12.2.
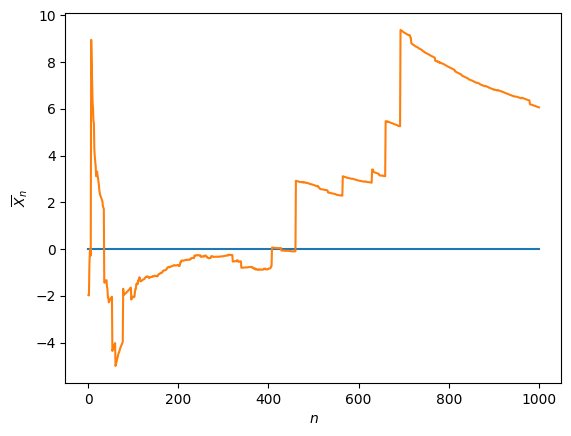
Fig. 12.2 Failure of the law of large numbers: average of \(n\) samples from the Cauchy distribution as \(n\to\infty\).#
12.3. The central limit theorem#
Again, we consider a sequence of i.i.d. samples \(X_1, X_2, \ldots\) with distribution function \(f\). We assume \(f\) has finite mean \(\mu\) and variance \(\sigma^2\).
By the law of large numbers, the shifted sample mean
has expectation 0.
Theorem 12.2 (Central limit theorem)
The distribution of the sequence of random variables
converges to the standard normal distribution as \(n\to\infty\).
Roughly speaking, we can write this as
where \(Z\) is a random variable following a standard normal distribution, or as
where \(\mathcal{N}(\mu,\sigma)\) denotes the normal distribution with mean \(\mu\) and standard deviation \(\sigma\).
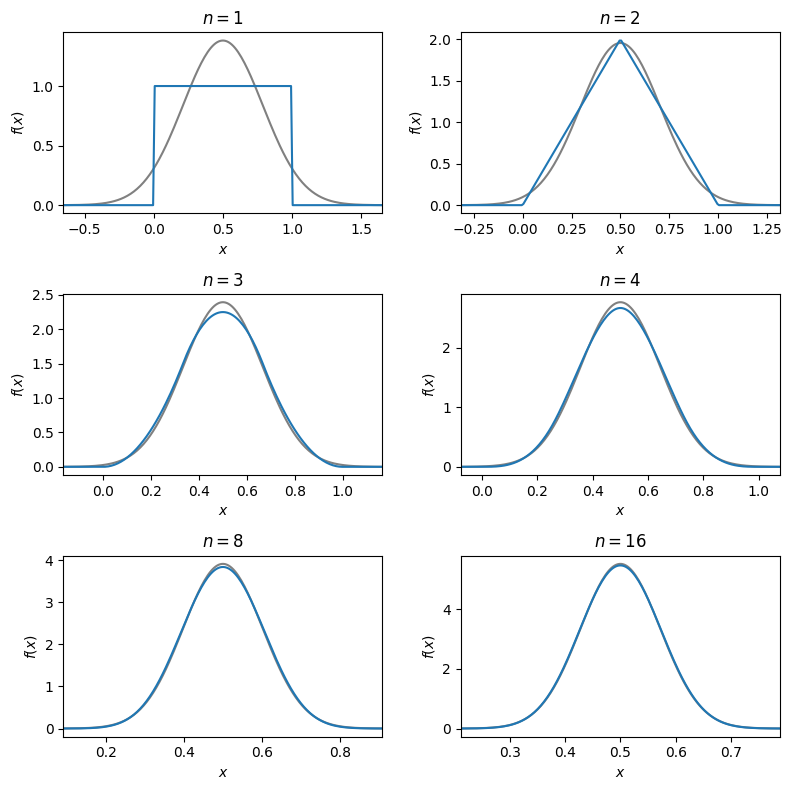
Fig. 12.3 Illustration of the central limit theorem for an average of \(n\) uniformly random samples#
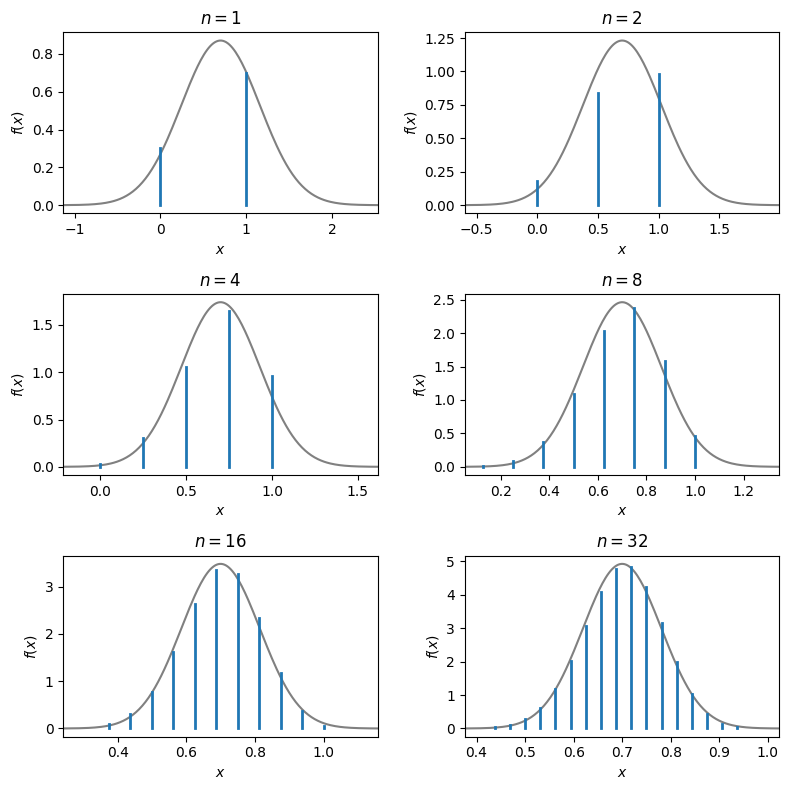
Fig. 12.4 Illustration of the central limit theorem for an average of \(n\) Bernoulli random samples (probability mass function scaled by a factor \(n\) for comparison with the probability density function of the normal distribution)#
The law of large numbers and a fortiori the central limit theorem are ‘well-known’ results, but their applicability relies on properties of random variables that are not necessarily satisfied in all cases. We already saw an example where the law of large numbers fails in Fig. 12.2. Likewise, one needs to be careful when applying the central limit theorem. Mathematical proofs help to clarify under what conditions these results hold and why. Perhaps surprisingly, a way to prove the law of large numbers and the central limit theorem is through Fourier analysis, via the characteristic function introduced in Section 10.9. We will not go into the details here.
12.4. Exercises#
Exercise 12.1
Suppose a certain species of tree has average height of 20 metres with a standard deviation of 3 metres. A dendrologist measures 100 of these trees and determines their average height. What will the mean and standard deviation of this average height be?
Exercise 12.2
Suppose \(X\) and \(Y\) are two independent continuous random variables which follow the standard normal distribution \(\mathcal{N}(0,1)\). In whatever programming language you like, compute and plot a histogram of \(n\) samples from \(X+Y\) for \(n = 100,1000,\) and \(10000\). What can you conclude about the random variable \(X+Y\)? Repeat the same exercise, but this time with \(X/Y\). What can you conclude about the random variable \(X/Y\)? Think about the central limit theorem as you explain your reasoning.